
Neat structures — Photo by John Jackson on Unsplash
Ask an LLM a well-put question and the likelihood is that you will get a sensible answer. Ask the same question again, though, and you might get an equally sensible but slightly different answer.
For example, I was trying to get an API to write executable code, and it turned out to be a challenge because no matter how many times and in how many places I told it not to, once in a while, it would put Markdown-style fencing around the code, making it syntactically wrong. (OK, it’s not too much of a problem filtering them out, but still…)
The responses from an LLM vary because there is always some randomness in processing the result. When using an API, you can reduce this with the ‘temperature’ setting, but, nevertheless, there will always be some variation.
If you are a human talking to ChatGPT, Gemini, Claude, etc., then this won’t matter. If the wording of the response is a bit different or the layout has changed, you still understand.
But if you are a computer program tuned to process one type of response, then even a slight variation may cause an error.
The solution is to use structured outputs to guarantee a consistent result.
We are going to look at how to create structured outputs using PydanticAI and apply them to a couple of use cases. First, we’ll see how structured outputs work, and then we’ll process unstructured data into a structured format that can be used programmatically. We’ll also see how we can generate runnable code reliably.
Why PydanticAI?
First, it’s open source and easy to use. And second, it is model-neutral: you can use it with several different LLMs (unlike OpenAI’s structured outputs, for example, that only work with their API).
Why Use Structured Outputs from an LLM
There are several benefits in using structured outputs over conventional responses, for example:
-
Reliability is improved— enforcing a predictable format will ensure the LLM response is consistent, and no complex parsing of the LLM response is required
-
Integration is easier — elements of a structured response can be used directly in an application or more easily processed into a required format
-
Development is faster — less code is required, and testing is less complex
Altogether, if you aim to use LLM responses in an application, structured outputs make life more straightforward.
What does a structured output look like
Typically, we are talking about JSON-like responses with specified fields and types. Such a structure can be easily used directly in a Python program as an array or dictionary, or may be converted into a Pandas dataframe or other data structure.
Take a look at the following message from a customer and the prompt.
complaint = """Hi, this is Jane. My internet has been down for two days
and I'm very upset."""
prompt = f"""
Extract the following information from the customer complaint:
Customer Name, Issue Category, Sentiment, Urgency.
Return your answer as a JSON object.
{complaint}
"""
We’re asking the LLM to analyse the customer complaint and produce a JSON response that will look something like the following.
{
"customer_name": "Jane",
"issue_category": "Connectivity",
"sentiment": "Frustrated",
"urgency": "High"
}
In this experiment, we will specify the structured output format a little more formally than this, and since the framework we are using is PydanticAI, it won’t be any surprise that we use Pydantic to define the output structure.
PydanticAI
PydanticAI is a fairly new framework for constructing AI agents. It’s MIT-licensed and pretty easy to use.
The following code is in the form of Jupyter Notebook cells, but you ought to be able to construct a plain old Python file from it, too. I’ll pop a link to the source code at the end of the article.
First things first, we need to import the Pydantic library, and so that it doesn’t interfere with the Jupyter runtime, we need to import nest_asyncio and run the apply method. You won’t need this in a plain Python program.
from pydantic_ai import Agent
import nest_asyncio
nest_asyncio.apply()
Simple structured output
This example comes from the PydanticAI documentation. We ask a simple question, and the answer should be a city. The response should be the name of the city and the country that it is in.
You can see in the code below that we have a very straightforward Pydantic declaration of a class CityLocation. It consists of two strings, one for the city name and the other for the country name.
The agent is defined with the model type and the result_type set to CityLocation , meaning that the response must be of that type.
We then run the agent with a query ‘Where were the olympics held in 2012?’ and print the result. This can be seen in the panel below the code.
from pydantic import BaseModel
class CityLocation(BaseModel):
city: str
country: str
agent = Agent('openai:gpt-4o-mini', result_type=CityLocation)
result = agent.run_sync('Where were the olympics held in 2012?')
print(result.data)
city='London' country='United Kingdom'
We could ask any question where the result is a city and receive a response in the same format. But what if the question does not produce a valid output? This could be due to an error in the LLM processing or because it is simply impossible to provide a suitable response to the question given.
In the case of an LLM failure, you probably need to validate the response against the Pydantic model and retry the query. There is a whole section on validation in the PydanticAI documents that deals with this, and it would take another article to deal with it, so I won’t go into it here.
However, when a valid answer isn’t possible, a simple strategy is to ask the LLM to fill in fields in the response that indicate whether a response is valid or not, e.g.
from pydantic import BaseModel
class CityLocation(BaseModel):
city: str
country: str
valid: bool = True
error: str = None
prompt = """If the answer is not a city,
return empty strings for the city and country,
return valid=False and an error message."""
agent = Agent('openai:gpt-4o-mini',
result_type=CityLocation,
system_prompt=prompt)
Here are a couple of queries, one bad, the other good:
result = agent.run_sync('What is a fish?')
print(result.data)
result = agent.run_sync('In what city was the soccer world cup final last played?')
print(result.data)
And the results:
city='' country='' valid=False error='The answer provided is not a city.'
city='Lusail' country='Qatar' valid=True error=None
So, that’s how to get structured outputs from an LLM. Let’s take a look at a couple of practical examples that might form part of an application.
We’ll first look at how we can transform unstructured customer feedback into a form that we can load into a Pandas dataframe for processing, and then we’ll see how we can generate runnable Python code.
Structured customer feedback
I’m going to use fictitious customer feedback similar to my AI for BI article Transform Customer Feedback into Actionable Insights with CrewAI and Streamlit. It is a set of ratings and comments about products from a made-up online shoe store.
I’ve stored the comments in a Markdown file called shoes.md, and so we can read it like this:
fb_raw = "shoes.md"
with open(fb_raw, 'r') as f:
fb = f.read()
print(fb)
When printed, it looks like the following: a star rating and a comment about the product.
# Customer feedback
### CloudStrider Sneakers
1. Stars: 2
"The shoes were super comfortable initially, but after just two months, the sole started to peel off! Really disappointed with the durability."
2. Stars: 1
"I ordered my usual size, but these sneakers were way too tight. Had to return them. The sizing is totally off."
3. Stars: 3
"Great for short runs, but they hold onto odors even after washing. Not ideal for heavy use."
4. Stars: 5
"Extremely lightweight and breathable. Perfect for casual jogging. No issues so far!"
### PeakTrek Hikers
1. Stars: 1
"These boots claim to be waterproof, but my feet were soaked after just walking through damp grass. Not worth it."
2. Stars: 2
"I slipped multiple times on rocky trails because the soles don’t grip well on wet surfaces. Not safe for serious hikes."
3. Stars: 4
"The boots are sturdy and provide decent ankle support, but I wish the padding was thicker for longer treks."
4. Stars: 5
"Used these for a weekend hike in the mountains, and they held up really well. No blisters, and they felt solid."
I want to transform this into a structured format, and I use the following prompt:
description=f"""
Analyse '{fb}' the data provided - it is in Markdown format.
The data is about the range of shoes in an online shop each with
set of messages from customers giving feedback about the shoes that they have purchased.
"""
This is used along with two Pydantic models: the first is the format of an individual comment, while the second defines a list of those comments. An Enum is used to define the possible sentiment values.
The agent is then called using the list as the structured output definition.
from pydantic import BaseModel
from enum import Enum
class Sentiment(str, Enum):
negative = 'negative'
neutral = 'neutral'
positive = 'positive'
class feedback_report_shoe(BaseModel):
product: str
overall_rating: int
issue: str
review: str
sentiment: Sentiment
class feedback_report(BaseModel):
feedback: list[feedback_report_shoe]
agent = Agent('openai:gpt-4o-mini', result_type=feedback_report)
result = agent.run_sync(description)
The result, in JSON format, can be seen using the following print statement.
print(result.data.model_dump_json(indent=2))
And here is a sample of that output:
{
"feedback": [
{
"product": "CloudStrider Sneakers",
"overall_rating": 2,
"issue": "Durability",
"review": "The shoes were super comfortable initially, but after just two months, the sole started to peel off! Really disappointed with the durability.",
"sentiment": "negative"
},
{
"product": "CloudStrider Sneakers",
"overall_rating": 1,
"issue": "Sizing",
"review": "I ordered my usual size, but these sneakers were way too tight. Had to return them. The sizing is totally off.",
"sentiment": "negative"
}
...
]
}
Now that we have a nicely structured output, we can easily convert it into a dataframe for further processing.
import pandas as pd
df = pd.DataFrame([dict(f) for f in result.data.feedback])
df['sentiment'] = df['sentiment'].apply(lambda x: x.value)
df
This code will give us the dataframe illustrated below.
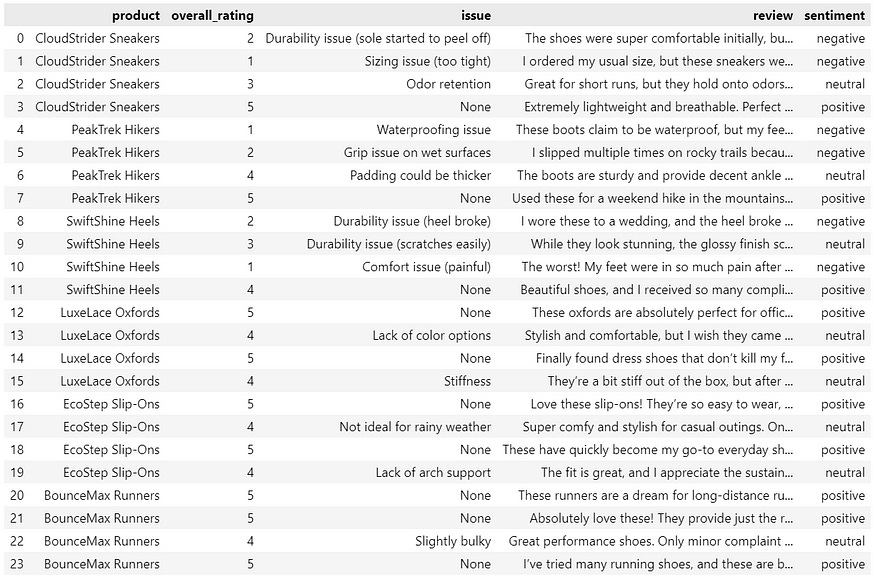
We can process the data further, for example, ranking the products according to their star rating.
average_ratings = df.groupby('product')['overall_rating'].mean()
average_ratings = average_ratings.sort_values(ascending=False)
print(average_ratings)
We first grouped the products, calculated the mean of the rating and then sorted them.
BounceMax Runners 4.75
EcoStep Slip-Ons 4.50
LuxeLace Oxfords 4.50
PeakTrek Hikers 3.00
CloudStrider Sneakers 2.75
SwiftShine Heels 2.50
In this example, getting the LLM to structure the data makes it easy for us to process it. Now, let’s look at my code generation problem.
Unstructured code generation
LLMs are quite proficient at producing code, but, as I discussed earlier, getting them to produce something consistent and usable is slightly trickier.
Here is a simple example of code generation. We simply asked the agent to produce a Python function to add two integers.
from pydantic_ai import Agent
agent = Agent(
'openai:gpt-4o-mini',
)
result = agent.run_sync("Write a Python function to add two integers"
"together and give an example call")
print(result.data)
Here is a simple Python function that takes two integers as input,
adds them together, and returns the result:
```python
def add_two_integers(a, b):
"""
Add two integers together.
Parameters:
a (int): The first integer.
b (int): The second integer.
Returns:
int: The sum of the two integers.
"""
return a + b
# Example call
result = add_two_integers(5, 3)
print(result) # Output: 8
In this example, the function add_two_integers is defined to take two
parameters, a and b. It calculates the sum of these two integers and
returns the result. The example call at the bottom demonstrates how to use
the function by adding the integers 5 and 3, resulting in an output of 8.
The result is typical of a chat-like response and contains exactly the right information. But I cannot use the output to directly run the code because the response is targeted at a human not a computer program.
Structured code generation
Here is a different version with a Pydantic model defined to split the output into the code section and a commentary.
class Code_Output(BaseModel):
code: str
commentary: str
agent = Agent('openai:gpt-4o-mini', result_type=Code_Output)
result = agent.run_sync("Write a Python function to add two integers"
"together and give an example call")
The code part of the response contains a runnable function — no additional information or Markdown fencing, just the code.
print(result.data.code)
def add_two_integers(a, b):
"""
This function takes two integers and returns their sum.
"""
return a + b
And the commentary contains the rest of the output.
print(result.data.commentary)
# Example call
result = add_two_integers(5, 3)
print(result) # Output: 8
The function 'add_two_integers' is defined to take two integers as parameters
and return their sum. An example call is provided where the function is
called with the integers 5 and 3, and the result is printed.
We can run the code easily. Here is a Notebook cell that does just that. The functional part of the cell is just exec(result.data.code). The rest of the code ensures that the user can review the code and is warned that running it could cause problems. It is a bad idea to run LLM-generated code unseen unless it is in a sandbox environment such as Docker. LLMs make errors and while it is unlikely that a function to add two integers will cause any harm, we should still check.
import ipywidgets as widgets
text = widgets.HTML("<h3>Running the code is potentially dangerous</h3>")
button = widgets.Button(description="Run it, anyway",
button_style='danger')
output = widgets.Output(layout={'border': '1px solid black'})
with output:
print("Code result:")
display(widgets.VBox([text,button, output]))
def run(b):
with output:
exec(result.data.code)
button.on_click(run)
VBox(children=(HTML(value='<h3>Running the code is potentially dangerous</h3>'), Button(button_style='danger',…
Conclusion
Structured outputs are a useful way of ensuring consistency in an LLM’s response, as I hope these simple examples have illustrated.
They are easily implemented in PydanticAI: simply define a Pydantic model and use that in the call to the AI agent. The result will be a data structure that is easily used in further coding.
I haven’t properly covered what happens if the LLM does not respond as required, which is always a possibility, as this could easily be a lengthy discussion. The method that I showed above only copes with the simplest of errors, and more sophisticated error detection may well be necessary for a particular application, for example, validation against the model and retrying the query - PydanticAI discusses this in their docs.
As ever, thanks for reading and I hope that this has been useful. To see more of my articles, follow me on Medium or subscribe to my Substack.
The code and data for this article can be found in my GitHub repo. I will place a link to it here shortly after publication.