
Image by author with a little help from Microsoft Bing Image Creator (Ok, ok… a lot of help)
Running an LLM locally with Ollama is not difficult and implementing an agent with LlamaIndex is also straightforward. But don’t expect the same performance you get from Anthropic, OpenAI or Google.
Industrial strength AI runs on powerful servers with lots of resources. Nothing that lives on your desk can compete with that sort of power, so while we will attempt to implement something interesting and, hopefully, useful that will run on your day-to-day laptop, don’t expect miracles.
We’ll use Ollama to run a local LLM. It’s not the only choice, for example, LM Studio and GPT4All are possible alternatives, but Ollama works nicely with LlamaIndex, so we’ll go with that.
Likewise, LlamaIndex is not the only way to implement an AI agent but it’s pretty easy. I’ve already explored other alternatives: AI Agents vs. AI Pipelines: A Practical Guide to Coding Your LLM Application, which is based on CrewAI, and How to Build a ReAct AI Agent with Claude 3.5 and Python, which is a DIY approach - now it’s someone else’s turn.
Ollama
Ollama lets you run an LLM on your local machine. You can choose which model you want to run and Ollama will download and run it. The first thing to do is get yourself over to the Ollama website, download it and install it - just follow the instructions for your operating system.
When you’ve done that open a terminal, or command window, and type in the command to run Ollama, e.g.
ollama run gemma2:2b
This runs Ollama using Google’s gemma2:2b which is the smallest of the Gemma models and seems to run OK on a machine with 8 gigabytes of RAM. If you don’t already have that particular model locally, then Ollama will download it. When Ollama is running you are presented with a command prompt. There are several commands available, for example, the command, pull,will download a new model - check out the Ollama library web page to select a model. And look at the Ollama GitHub page for more details and commands.
The command line is an interface to the LLM. Here is an example of an interaction with the LLM from the command line.
»>Please list the presidents of the USA since 1990
Here are the presidents of the United States since 1990:
- George H. W. Bush (1990-1993)
- William Jefferson Clinton (1993-2001)
- George W. Bush (2001-2009)
- Barack Obama (2009-2017)
- Donald Trump (2017-2021)
- Joe Biden (2021-Present)
Let me know if you’d like any more information about these presidents or their presidencies!
The first line is my prompt and the rest is the LLM’s response (I’ve put in the emphasis for readability). It’s a good response and it wasn’t as slow as I thought it might be, so we are off to a good start.
To use Ollama in Python you will, of course, need to download the library from PyPi.
pip install ollama
Once you have done that and it is running you can ensure it works using the following code.
import ollama
def query(q: str)-> str:
response = ollama.chat(model='gemma2:2b', messages=[
{
'role': 'user',
'content': q,
},
])
return (response['message']['content'])
print(query("Why did the chicken cross the road"))
The LLM will respond with a message something like the following.
To get to the other side! 🐔😄
This is a classic joke! It's simple, silly, and always
a fun way to start a conversation.
Do you want to try telling another one? 😉
OK, now we are up and running. Let’s take a look at how we are going to implement a local agent.
Agents
Agents are LLMs that have access to external tools and can make decisions on how to use those tools to provide a solution to a problem. They typically run in a loop thinking step by step about how they should address a problem and which tools they need to invoke at each step.
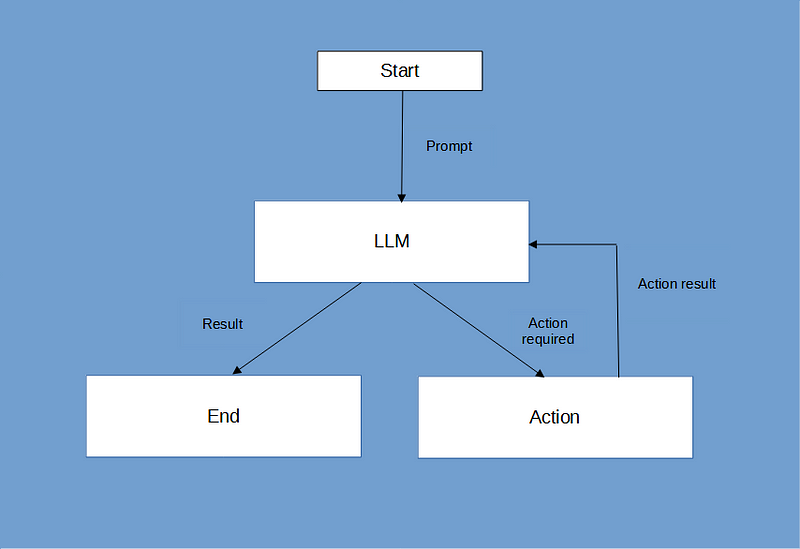
An AI agent flow chart
I’ve explored the use of agents in the articles I referred to above, this time I will demonstrate the use of LlamaIndex agents. We don’t need to go into the implementation but it might be useful to look at the prompt that is used to implement LlamaIndex agents as this is where much of the work is done.
We’ll look at the prompt a section at a time to work out just what is going on. (To be clear, LlamaIndex code is open-sourced under the MIT licence so we are permitted to use it pretty much how we like and we can reproduce it here.)
The prompts used in LlamaIndex code are implemented as templates, that is strings that contain placeholders for variable inputs (e.g. the names of tools that are provided to the agent). The prompt that we will examine here is the system prompt for a ReAct agent[1]. It is formatted as a Markdown document and starts with a very broad aim.
You are designed to help with a variety of tasks, from answering
questions to providing summaries to other types of analyses.
The prompt is then broken down into several sections. The first tells the LLM what tools are available to it.
## Tools
You have access to a wide variety of tools. You are responsible for using
the tools in any sequence you deem appropriate to complete the task at
hand but you should always use a tool if you are able in order to find
information. This may require breaking the task into subtasks and using
different tools to complete each subtask.
You have access to the following tools:
{tool_desc}
As you can see the LLM is told how to use the tools and {tool_desc}will be replaced with a list of the tool descriptions.
## Output Format
Please answer in the same language as the question but and use the following format:
Thought: The current language of the user is: (user's language). I need to use a tool to help me answer the question.
Action: tool name (one of {tool_names}) if using a tool.
Action Input: the input to the tool, in a JSON format representing the kwargs (e.g. input)
Please ALWAYS start with a Thought.
NEVER surround your response with markdown code markers. You may use code markers within your response if you need to.
Please use a valid JSON format for the Action Input. Do NOT do this input.
If this format is used, the user will respond in the following format:
Observation: tool response
You should keep repeating the above format till you have enough information to answer the question without using any more tools. At that point, you MUST respond in the one of the following two formats:
Thought: I can answer without using any more tools. I'll use the user's language to answer
Answer: [your answer here (In the same language as the user's question)]
Thought: I cannot answer the question with the provided tools.
Answer: [your answer here (In the same language as the user's question)]
This section describes the Thought, Action, Observation, Answer sequence which are the steps the agent goes through to arrive at a solution and specifies the format in which the LLM should respond.
Finally, the prompt tells the LLM that following this system prompt will be the messages that are generated by the user and responded to by the LLM.
## Current Conversation
Below is the current conversation consisting of interleaving human and assistant messages.
These sections are all joined into a single system prompt, which defines the behaviour of the agent.
LlamaIndex
This brings us to creating an agent in LlamaIndex. LlamaIndex has libraries that implement agents and one of these is the ReactAgent that incorporates the prompt that we saw above. We’ll implement an agent and specify some tools that it can use. Then we’ll see how it performs.
The first thing we need, of course, is to import some libraries.
from llama_index.core.tools import FunctionTool # allow function use
from llama_index.llms.ollama import Ollama # the Ollama library
from llama_index.core.agent import ReActAgent # the agent library
import wikipedia # the wikipedia library
Their use is pretty much self-explanatory: the first lets us define and add tools to the agent, the Ollama library is required so we can easily incorporate our local LLM and, of course, we need the library that allows us to create agents.
We import wikipedia because we are going to build a tool around it.
If you would like to follow along and implement the code as a Jupyter Notebook then each code block that I describe here can go into a separate cell. Alternatively, you can concatenate them into a single Python program.
We want our agent to have access to tools and so we need to specify functions that implement those tools. Here are a couple.
# define sample Tools
def evaluate(inp: str) -> str:
"""evaluate an expression given in Python syntax"""
return eval(inp)
def wikipedia_lookup(q: str) -> str:
"""Look up a query in Wikipedia and return the result"""
return wikipedia.page(q).summary
eval_tool = FunctionTool.from_defaults(fn=evaluate)
wikipedia_lookup_tool = FunctionTool.from_defaults(fn=wikipedia_lookup)
Here we define two tools: one looks up something on Wikipedia and the other evaluates a Python string. Both take strings as input and return strings as output. The type hints and documentation strings are important as these are used to tell the agent how to use the tools.
A note of caution here: the evaluate tool is useful and versatile as we can use it to solve mathematical problems - something that LLMs are not great at. However, it is inherently dangerous as it will run any Python code you give it - imagine a set of Python commands that imported the os library, used it to navigate to your root folder and then proceeded to delete all your files. This is not something that we would want to allow unrestricted access to. So, while this particular tool is convenient, it should be used with caution.
Following the tool function definitions, we need to create LlamaIndex tools to use them. I’ve named these eval_tool and wikipedia_lookup_tool. We will see how we inform the agent about them, shortly. Before that, we can do that we need to create an agent.
But first, we set up the LLM.
# initialize llm
llm = Ollama(
model = "gemma2:2b",
request_timeout=120.0,
temperature=0
)
We call this llm and it is the result of a call to Ollama from the Ollama library. In that call, we specify the model we will use (this should be the same as the one we’ve set running from the command line - obviously!), we set a timeout (2 hours! Things don’t normally take that long so you can make it much shorter if you want to) and we also set the temperature which is a measure of the randomness, or creativity, of the LLM’s response. A value of 0 gives you the least randomness and the most consistency but you may want to change this depending on the sort of work that you are doing.
Now we can create the agent that uses the LLM and the tools we have just defined.
agent = ReActAgent.from_tools([eval_tool, wikipedia_lookup_tool],
llm=llm, verbose=True)
That is all there is to creating an agent with Llamaindex. We give it a list of tools, the LLM and set verbose to True. This means that we will get a lot of feedback from the agent. As you might expect, you will get less feedback if you set it to False.
And there we are! Ready to run.
Let’s give it a try.
response = agent.chat("What is the population of the capital of France")
print(response)
A simple request that will invoke a call to the Wikipedia tool, get the information required, and then print out the result.
Here is an abbreviated readout of the session.
Running step dc619f8e-45ca-4cfc-8bd1-50ed2b9e64ea.
Step input: What is the population of the capital of France
Thought: The current language of the user is: English. I need to use a tool to help me answer the question.
Action: wikipedia_lookup
Action Input: {‘q’: ‘Paris’}
Observation: Paris (French pronunciation: [paʁi] ) is the capital and largest city of France. With an official estimated population of 2,102,650 residents in January 2023 in an area of more than 105 km2 (41 sq mi)…
(lots more about Paris here)
…Tour de France bicycle race finishes on the Avenue des Champs-Élysées in Paris.
Running step d7d0c129-dfe1-45a5-9db0-81e43ca6debf.
Step input: None
Thought: I can answer the question without using any more tools.
Answer: The population of the capital of France, Paris, is estimated to be around 2,102,650 residents.
I’ve highlighted the stages that it has worked through like a good little agent, so you can easily see its ‘thought process’. You can see how it has chosen a tool, called it and used the response to work out the answer to the question.
Next, we have a simple use of the eval tool.
response = agent.chat("""What is 2 * (5 + (6 * 4))""")
print(response)
We are asking the agent to solve a simple arithmetic expression and it does exactly that.
Running step c8347df9-10c7-4d34-8b78-2540521e6e7b.
Step input: What is 2 * (5 + (6 * 4))
Thought: I need to use the evaluate tool to calculate this expression.
Action: evaluate
Action Input: {‘inp’: ‘2 * (5 + (6 * 4))’}
Observation: 58
Running step 58981d08-1b5d-4658-80e5-21ecb4503665.
Step input: None
Thought: The answer is 58.
Answer: 58
The agent simply extracts the expression from the input and passes it to the tool for evaluation.
We’ve done what we set out to do - we have a locally running LLM and a pattern for how we can use it programmatically with LlamaIndex agents. But let’s go just a little bit further.
With this simple set up we can even create a basic workflow.
A simple workflow
LlamaIndex provides support for workflows within its framework and you can also use other frameworks such as LangChain, or CrewAI, to do the same thing.
These products give you very sophisticated ways of orchestrating flows between agents and tools. But if you use a single agent with a simple linear flow, a workflow boils down to a list of prompts and a loop.
Here is an example of a workflow that consists of two prompts. It is a tool for creating summaries of information suitable for kids. The agent will look up a subject in Wikipedia, construct a summary of that information, and, finally, rewrite it using language that is good for a young reader.
# A crude workflow
def kids_query(subject):
prompts = [f"""Find out about {subject} and summarize your findings
in about 100 words and respond with that summary""",
"""Re-write your summary so that it is suitable for a
7-year old reader"""]
for p in prompts:
response = agent.chat(p)
return response # return the last response
It’s a simple function definition that incorporates a list of two prompts. The first instructs the agent to look up a topic and produce a 100-word summary. The second prompt tells the agent to re-write the summary in language aimed at a 7-year-old reader. The topic to look up is set as a parameter so we can write any topic in there and inform our young reader of a whole range of subjects.
We run through a loop to send each prompt to the agent. The response from the agent is recorded in the variable response and the last of these responses is passed back as the return value.
Here is an example.
print(kids_query("Madrid"))
This results in the following.
Running step 5489cdff-2845-424e-8cca-56d2a7b5da17.
Step input: Find out about Madrid and summarize your findings in about 100 words and respond with that summary.
Thought: (Implicit) I can answer without any more tools!
Answer: Madrid is the capital of Spain, a vibrant city known for its rich history, art…
more stuff about Madrid, here
Running step d5ecf385-6846-4e40-b244-5c84c731f9b4.
Step input: Re-write your summary so that it is suitable for a 7-year old reader
Thought: (Implicit) I can answer without any more tools!
Answer: Madrid is like a big city with lots of cool stuff! It has fancy palaces and museums where you can see amazing paintings and sculptures. You can even go dancing in the evening! Madrid also has yummy food, just like your favorite pizza place! It’s a fun place to visit!
This is simple and I hope that you can see that using a parameterised function makes the workflow more easily generalisable. Imagine now if the agent is passed as a parameter, too. Your program would then be able to use multiple agents. And if we also passed in the list of prompts, we would be well on our way to constructing our own multi-agent framework.
Conclusion
Of course, a locally running LLM is not going to be as powerful as one supplied online by one of the big players. But I hope that I have demonstrated that a local LLM is pretty easy and could be useful. If, for example, you want to incorporate private data into your app and are nervous about them being uploaded to an external website then this might be a way forward for you.
You have to bear in mind that a local LLM will use a lot of resources and while it is working you may well notice that your laptop slows down. Also, as you might expect, things take longer. It might take a minute or so to respond to the simple prompts I’ve demonstrated here. To do any sort of data analysis is also slow (that is why I set the timeout to 2 hours!). I haven’t included any data analysis examples here because I have not been satisfied with the results I have obtained, so far - maybe next time.
Thanks for reading, I hope that this article has been useful. All code and examples are available in my Github repo - feel free to download them. To be informed when I publish articles please subscribe to my occasional newsletter or follow me on Medium (if you are a member).
Notes and references
- Shunyu Yao, et al, ReAct: Synergizing Reasoning and Acting in Language Models, The Eleventh International Conference on Learning Representations (ICLR), 2023. (retrieved from https://arxiv.org/pdf/2210.03629, 27/06/2024)
All images and illustrations are by me the author unless otherwise noted.
Disclaimer: I have no connection or commercial interest in any of the companies mentioned in this article.